Abstract
#### Le cadriciel Semantic_forms: vers le SI Sémantique
Au départ, il y avait ce constat : il n'a pas de solution
Open Source simple pour visualiser et éditer des données RDF
en s'appuyant sur une base SPARQL, et sur les ontologies, de
manière collaborative. On est parti d'un générateur de
formulaire robuste, générique, et en temps réel. Puis on a
élargi les fonctionnalités pour proposer un framework Web
(cadriciel disent nos amis Quebécois) qui vise à être aussi
simple et universel que Ruby on Rails, Django, Symphony,
etc. On a aussi posé des jalons pour une console
d'administration SPARQL ( à la PHPMyAdmin ). Au passage on
élargira le propos sur le Système d'Information avec les
avantages du Sémantique, et l'ERP (Progiciel de Gestion
Intégrée) sémantique.
**Cas d'utilisation**
* Semantic_forms est fonctionnel en sortant de la
boîte, une fois qu'on a dézippé le logiciel, ou qu'on
l'a construit à partir des sources. Pas besoin
d'installer séparément une base de données ou d'autres
composants. Vous pouvez naviguer dans vos données RDF
(Turtle, JSON-LD) chargées dans la base locale Jena
TDB aussi facilement que dans les profils FOAF sur
Internet, ou mélanger les deux. Semantic_forms
ressemble aux pages de DBPedia, où en plus on peut
modifier tous les champs, et charger n'importe quelles
données du LOD.
* Si on n'est pas content du formulaire créé
automatiquement, on peut écrire une spécifications de
formulaire. On peut aussi composer des pages Web
statiques qui appellent via JavaScript un ou plusieurs
services Web de formulaires.
**La technique**
En ce qui concerne la mise en œuvre, semantic_forms
tire parti de Jena TDB (en embarqué), de Play!
Framework, du langage Scala et de la librairie
Banana-RDF. Grâce à Banana-RDF, on peut peut
configurer semantic_forms pour utiliser d'autres bases
de données SPARQL, en embarqué (via API) comme
BlazeGraph ou Sesame, ou n'importe quelle base via
HTTP.
**Les composants**
* librairie de génération de formulaires (API Java
et Scala)
* application Web générique avec Play! framework
* cache SPARQL, utilise un graphe nommé par source
de source de données, plus un par utilisateur
* le cache, via LDP, peut être utilisé comme un
composant d'infrastructure qui fédère des données de
différentes provenances
* divers algorithmes: dédoublonnage, restructuration
d'ontologie
* composant IHM de création de liens vers des URI
dbPedia
 Semantics_Forms-JeanMarc_Vanel.pdf
Semantics_Forms-JeanMarc_Vanel.pdf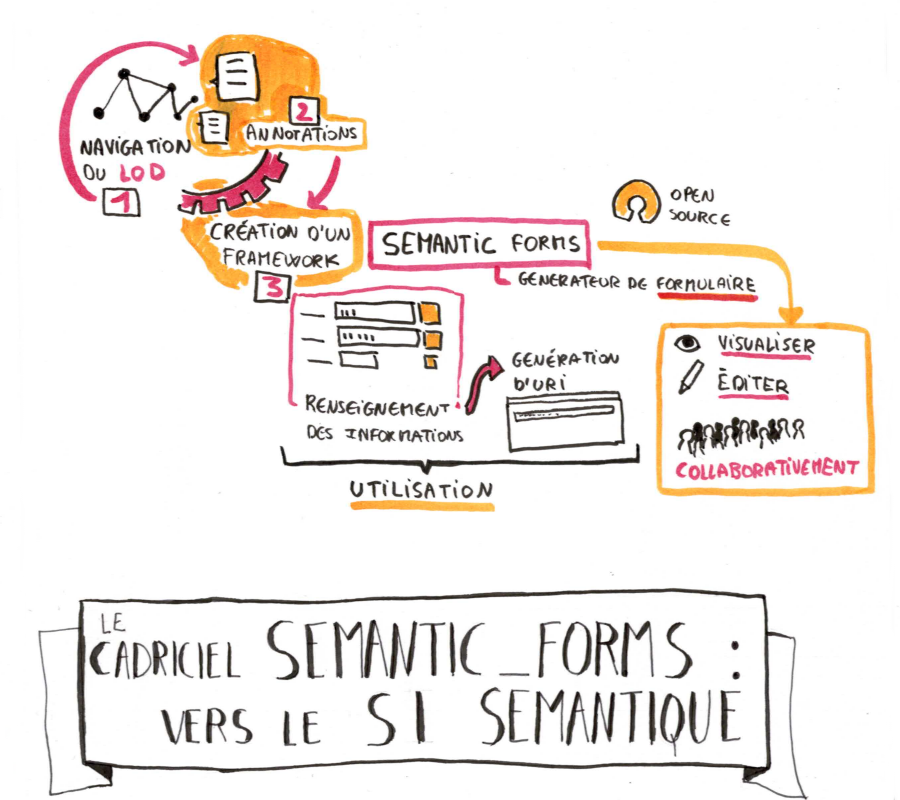 cadriciel.png
cadriciel.png