Abstract
Le métier de Proxem est de collecter un corpus de
documents sur un domaine spécifique, de l’organiser, puis
celui-ci organisé, d’extraire de l’information au niveau
du corpus entier. L’étape d’organisation comprend
généralement deux étapes : une étape d’annotation
(extraction de concepts organisés selon un thésaurus) puis
une étape de classification via une certaine taxonomie
définie avec le client. L’étape d’annotation nécessite un
paramétrage adapté au domaine du corpus et donc
généralement de connaître l’univers associé, sa
terminologie, etc. Par ailleurs, une approche type « page
blanche » cause des problèmes de taux de couverture.
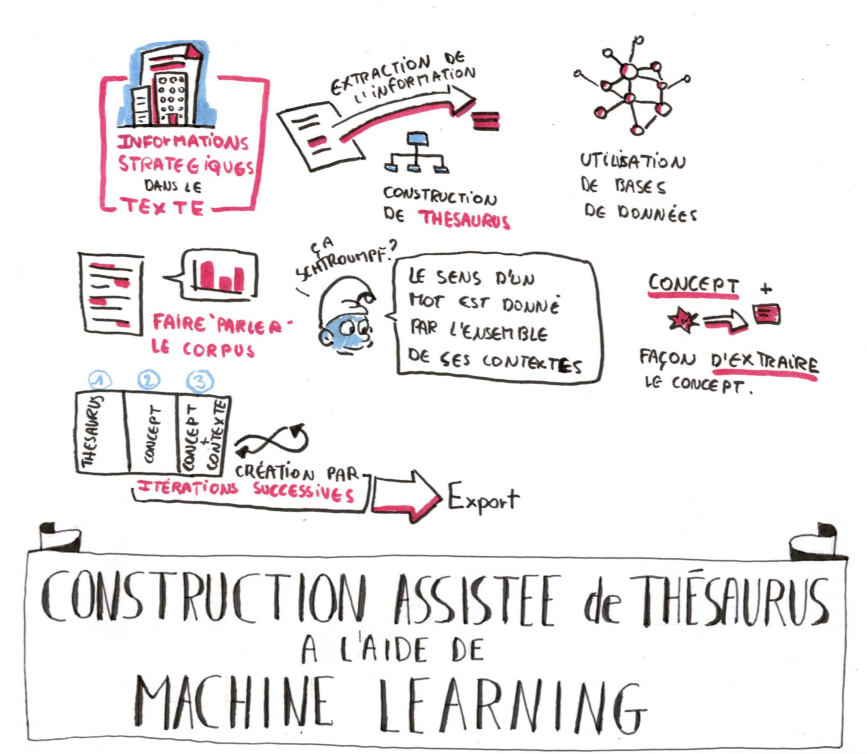
Dans l’optique de répondre à ce problème, Proxem a
développé une solution de construction de thésaurus
assistée par Machine Learning, via une double approche :
* Une approche bottom-up : après une étape d’apprentissage
non-supervisé réalisé sur le corpus (calcul de clusters, de
représentations distributionnelles de termes, etc.), l’ordinateur
fait des propositions à l’utilisateur et ce dernier valide ou
invalide ces propositions. Ensuite, via une démarche itérative,
l’ordinateur prend en compte les décisions de l’utilisateur, et
essaie d’améliorer ses propositions.
Le nommage des clusters se fait via l'importation des données de
WikiData.
Une approche top-down : l’utilisateur importe de la
connaissance du monde, via par exemple de la donnée
structurée existante. Cette donnée structurée permet
d’apprendre des modèles d’apprentissage supervisés que
l’on utilise directement sur notre corpus en inférence.
Il peut également importer des bases de connaissances au
format SKOS (ESCO pour les Ressources Humaines, EuroVoc,
GEMET, AGROVOC, etc.)
Pour chacun des concepts du thésaurus, l’ordinateur
propose plusieurs façons d’extraire le concept dans le
corpus (désambiguïsation via termes activateurs et
inhibiteurs, modèle d’extraction d’entités nommées
pré-appris, etc.). L’ordinateur propose directement les
termes correspondants aux concepts dans les autres
langues, permettant ainsi la création d’un thésaurus
multilingue, exportable au format SKOS.
Une fois que l’utilisateur est satisfait du thésaurus, il
peut ensuite s’en servir pour annoter son corpus et
indexer les annotations afin de les requêter dans un
moteur de recherche et d'obtenir les résultats en
affichant les mots en contexte comme le ferait un
concordancier.
#### Auteurs
**Jean-Marc Marty**
Diplômé de l’Ecole Polytechnique en 2014, Jean-Marc
Marty a rejoint l’équipe de Recherche et Développement de
Proxem pour développer les technologies d’analyse sémantique
de l’entreprise. Il est plus particulièrement spécialisé
dans l’apprentissage de modèles de langues et dans le
développement de modèles statistiques en vue de la
classification cross-langage de documents.
 construction_thesaurus.png
construction_thesaurus.png